
WikiBonsai: A Legible Knowledge Layer
Structured Plain Text For Any AI Agent, Model, DB -- And It's Human-Readable Too


What does a persistent semantic knowledge layer need to be? What separates an agent that retrieves from an agent that understands?
WikiBonsai started as a personal knowledge management methodology, built from first principles in cognitive science. Specifically, it focuses on how understanding develops. It wasn’t about storing information more efficiently. It was about helping people generate the kind of structure that makes information navigable, composable, and meaningful.
Then AI agents arrived and reframed the question entirely: What does a persistent semantic knowledge layer need to do? These turned out to be the same questions WikiBonsai was already trying to answer, just from a different direction. WikiBonsai was built for human learners. But the structure that helps humans understand a domain deeply is the same structure that lets any system do more than simply retrieve.
To see why that matters, consider the difference in how a junior developer and a seasoned software architect reason about an unfamiliar code base. The junior developer can look things up —- documentation, stack traces, prior issues. But the architect does something different: They construct a domain of mental models that cohere. They know which components are foundational and which are peripheral, which systems depend on which, where a new bug is likely to propagate...When a new piece of information arrives, the junior developer appends it to a list of things they know. The architect places it into a structure. They know immediately whether it confirms or complicates, whether it belongs to this part of the system or that one.
Novices have facts. Experts have structure. That structure is made up of both the hierarchy of dependency and abstraction, and the web of lateral associations between concepts that don’t share a direct parent-child relationship. These are distinct things. Hierarchy tells you what depends on what. Topology tells you what relates to what. Expert understanding has both. A flat list of retrieved facts has neither.
This is precisely what WikiBonsai implements. Not a filing metaphor. Not a storage container. A structural model of how understanding actually works, built from the ground up, to reflect the shape that understanding takes in a mind. It extends markdown with just three primitives. Each one maps to a fundamental graph concept. Together, they form a knowledge architecture in plain text.
The Primitives
wikirefs
The first primitive is [[wikirefs]]. It’s similar to the [[wikilink]] syntax, except it extends the original syntax with more modern expectations often found in PKM, as well as providing the building blocks to form a semantic web across markdown files with typed relationships between notes.
It includes traditional wikilinks, typed wikiattrs, and embedded content with wikiembeds. The first two are our primary concern with respect to the graph: A plain [[wikilink]] creates an edge between two concepts. A :typed::[[wikiattr]] names that relationship explicitly:
// note.md
a good book on [[reading]] is about [[bk.how-to-read-a-book]].
// bk.how-to-read-a-book.md
: tag :: [[reading]]
Supporting both typed and untyped links means relationships between concepts can formalize over time. They can start out vague and ambiguous and sharpen as understanding deepens. An untyped link says “these two ideas are connected, though I’m not sure why.” A typed link says “Here is how.” The spectrum from untyped to typed mirrors the spectrum from familiarity to understanding. You can start noting connections and define them more clearly as your grasp of a domain develops.
With flexible linking, node relationships can solidify as understanding does.
CAML
The second primitive is Colon Attribute Markup Language or CAML for short. It’s a clean, YAML-like syntax for structured attributes with two features plain YAML doesn’t have: Native [[wikiref]] support and flexible document placement.
// reading.md
: title :: Reading
: related :: [[writing]]
It’s important to alternate between reading and writing about what we read.
: see-also :: [[reading-goal]]
How we read is also determined by the goal. For example, reading for entertainment is very different than reading to achieve understanding.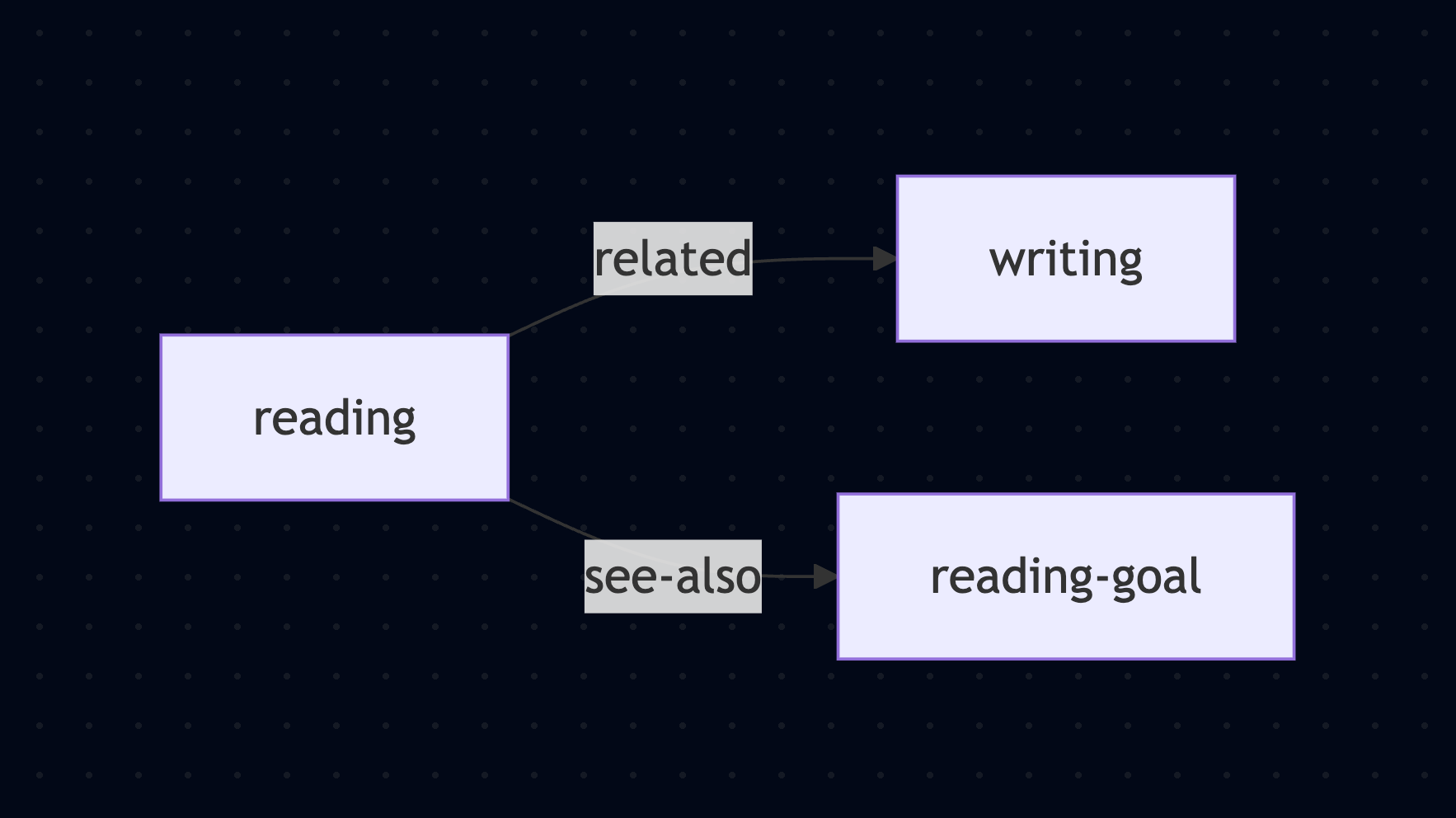
Typically, YAML can only read attributes within frontmatter delimiters found at the top of a file. CAML can be sprinkled throughout a file. This way, attributes appear where they’re relevant, not just where the format permits.
CAML provides a way to clarify node relationships by naming the relationships between linked files. But we also need to organize those files.
semtree
The third primitive is semtree, which is short for “semantic tree.” It’s an explicit hierarchy defined across markdown files. Where wikirefs create a semantic web of lateral link relationships, semtree provides the backbone that is the semantic tree: A single unified hierarchy that tells you where each concept sits relative to others in that hierarchy.
// i.learning.md
- [[critical-thinking]]
- [[i.reading]]
- [[writing]]
// i.reading.md
- [[active-reading]]
- [[reading-comprehension]]
- [[i.4-levels-of-reading]]
- [[reading-goals]]
- [[reading-for-amusement]]
- [[reading-for-information]]
- [[reading-for-understanding]]
// i.4-levels-of-reading.md
- [[elementary-reading]]
- [[inspectional-reading]]
- [[analytical-reading]]
- [[syntopical-reading]]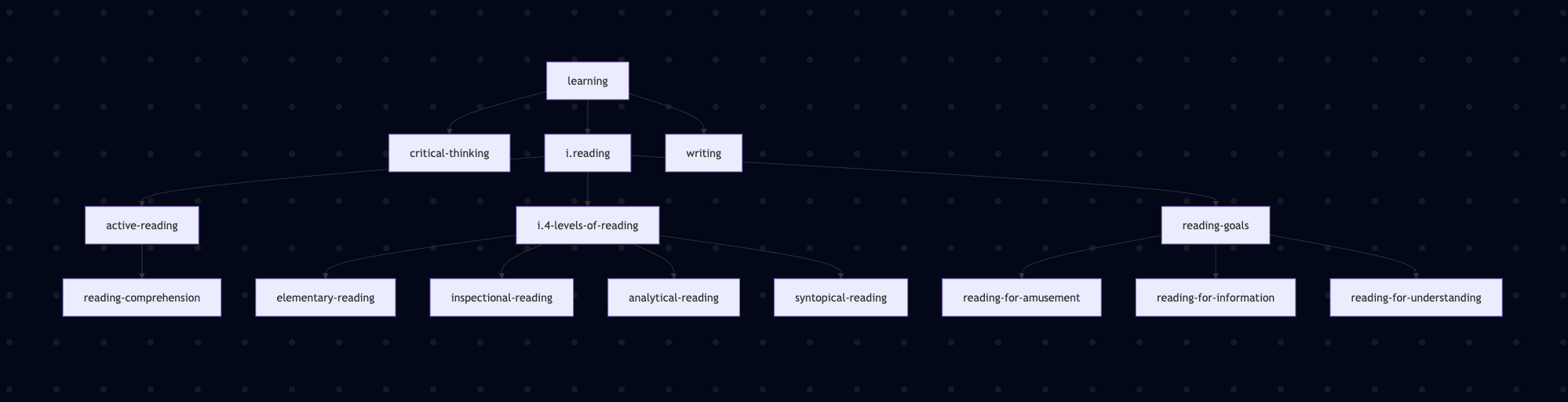
By defining this hierarchy in markdown, WikiBonsai creates a clean separation of concerns between semantic hierarchy and file organization, which frees the directory structure for whatever organizational scheme fits your workflow. Think of it like the difference between a table of contents and an index in a book: One orders concepts by meaning and dependency, the other organizes for navigation and lookup. semtree is the table of contents, while your directory structure can act like an index. Both serve different purposes. WikiBonsai lets you use both.
What This Looks Like
When wikirefs, CAML, and semtree are combined across a collection of markdown files, something emerges that is greater than the sum of its parts: A structured knowledge base that is simultaneously a semantic network, a navigable hierarchy, and an annotated graph.
This is what it looks like:
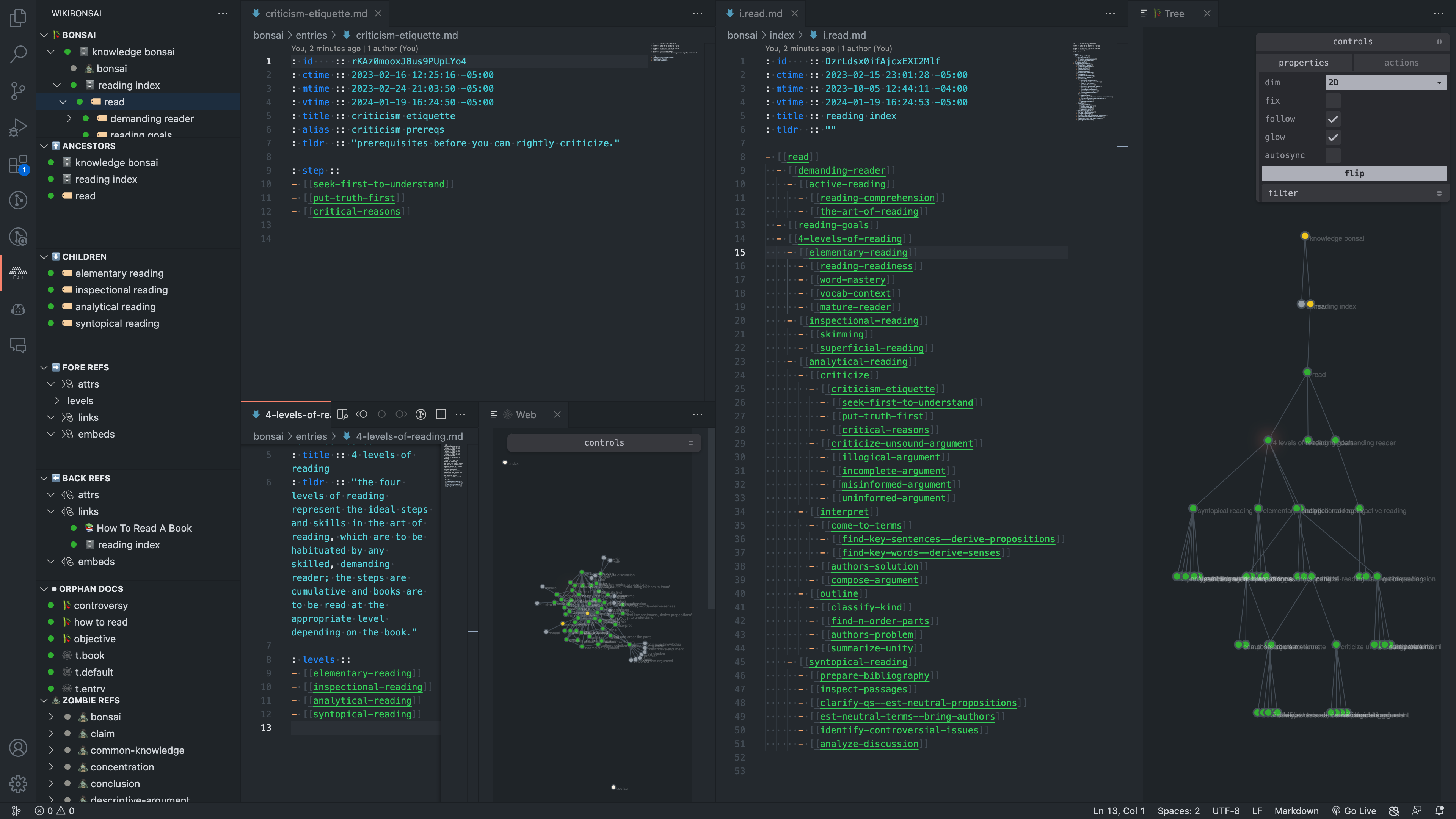
Every node is a markdown file. Every edge is a wikiref. Every position in the hierarchy is defined by the tree. Because the structure lives in plain text, it is legible to anyone who can read it: A person, an LLM, a database, a script. It can be crafted by hand, grown note by note. Or it can be seeded and scaffolded automatically. Either way, what you see is exactly what is there. No inference layer. No queries required.
All of this is live and usable with the vscode-tendr extension.
The Legibility Argument
Everything described so far operates on plain markdown files. No database running in the background. No embeddings to compute or recompute when you switch models. No proprietary format locking your knowledge to a particular tool or vendor. Just files. Files that git can version, any editor can open, and any language model can parse without preprocessing.
This matters more than it might seem. Most knowledge systems today make an implicit tradeoff: Structure in exchange for legibility. A graph database gives you traversable relationships, but locks them behind a query layer. A vector store gives you semantic similarity, but locks it behind an embedding pipeline. The structure is real, but accessing or migrating it requires either the system that produced it or nontrivial export work. Change the system and you may lose the structure entirely.
WikiBonsai does something different: The structure is in the text. Readable by humans, any LLM, any model, any DB, any script, today, tomorrow, or twenty years from now. The knowledge, and its structure, belong to you. Starting up a new AI agent draws from a coherent set of memories. Switch from one language model to another and your knowledge architecture comes with you. If the tooling changes, if a company shuts down, if you want to inspect or edit the knowledge base directly -- you can. It’s just a folder of markdown files. Nothing is hidden. Nothing requires a running system to see the raw data.
A Shared Map
WikiBonsai was originally built for human learners. The semantic tree and the semantic web are direct implementations of what cognitive science describes as knowledge organization: The structure that separates someone who has merely encountered a domain from someone who understands it.
As it turns out, that same structure is exactly what any system needs to do more than retrieve from a knowledge base. The questions an AI agent needs to answer are the same questions a human with deep understanding answers effortlessly because the structure is already in place: What is fundamental here? What depends on what? Where does this new piece of information fit?
Retrieval is not understanding. A list of facts is not a map.